Блискавичний старт — без складнощів
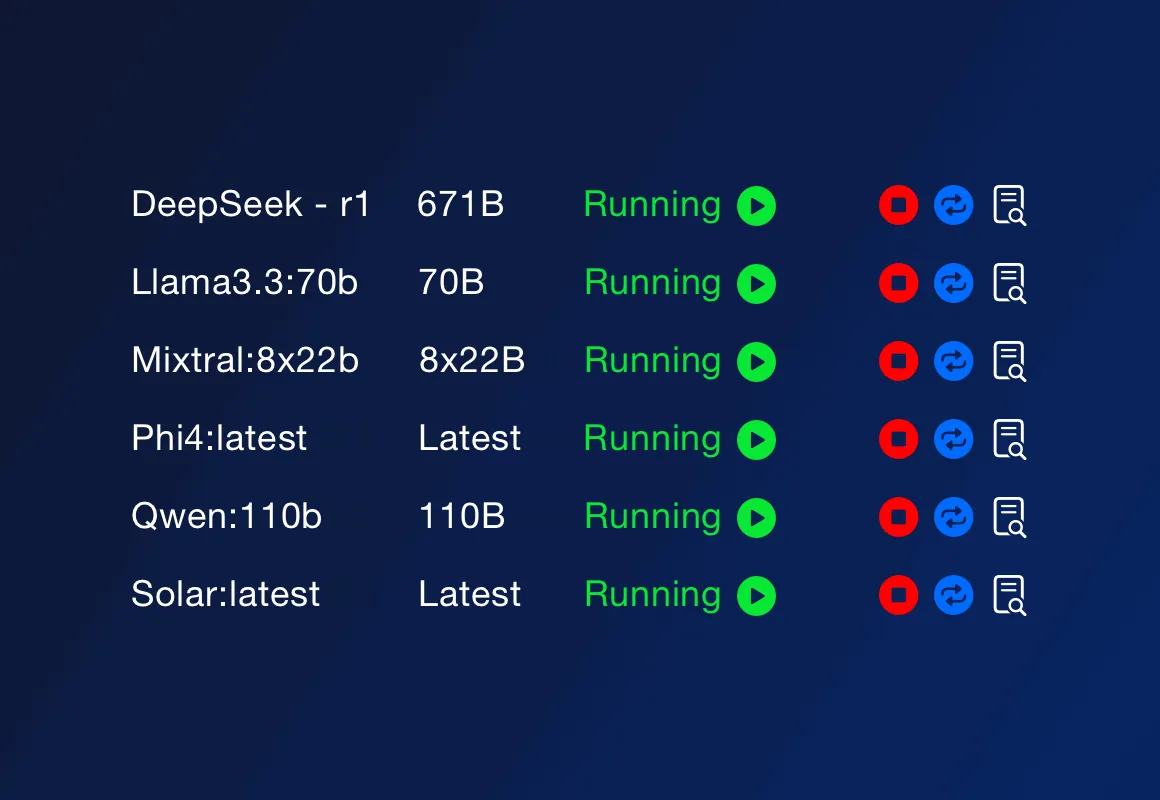
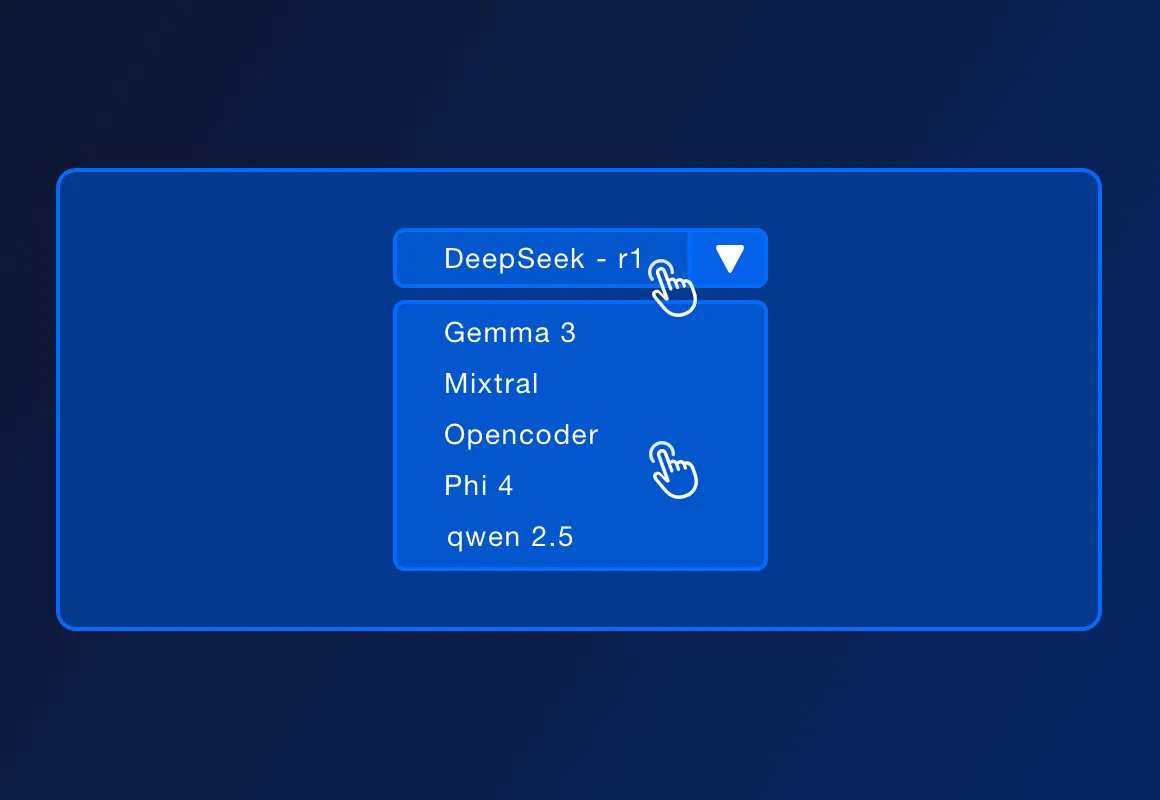
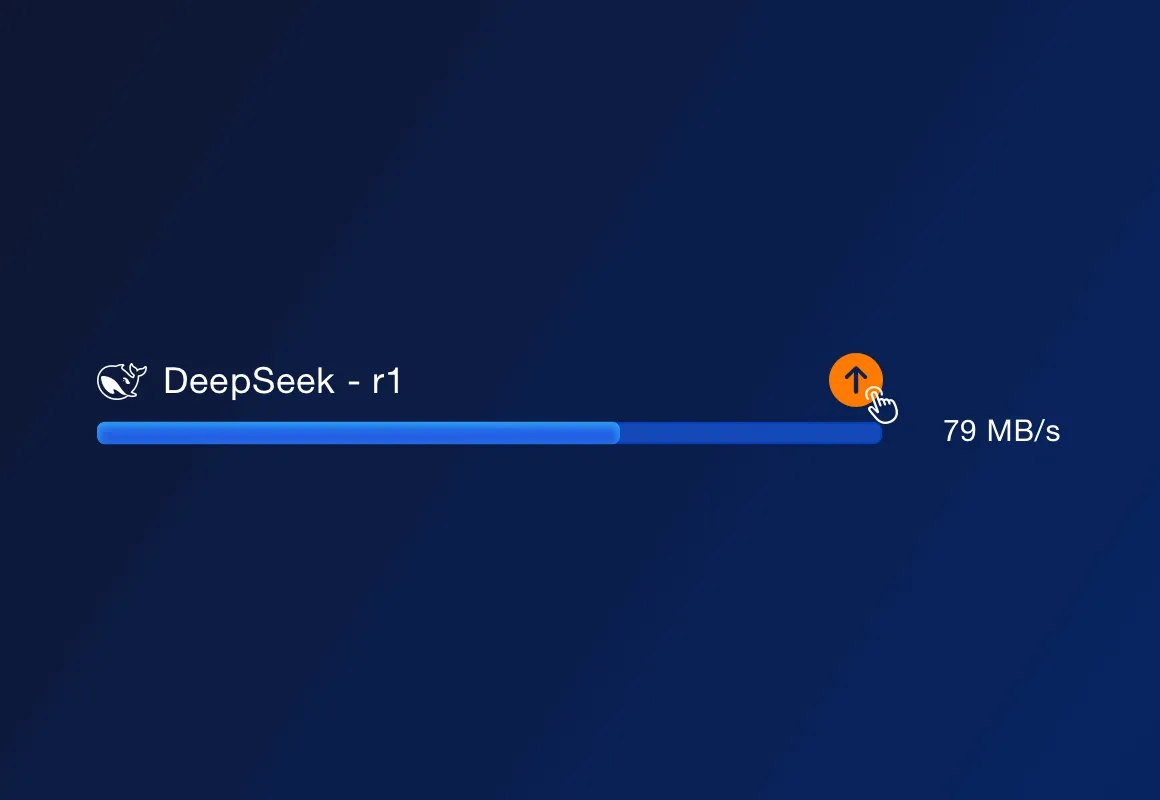
Поки класична установка Ollama вимагає ручних налаштувань, у ServBay усе гранично просто: виберіть модель (від 1.5B до 671B), клікніть "встановити" — і система сама потурбується про залежності та ресурси. Навіть новачок легко впорається!